Next Generation Large-scale Training Algorithms with Deterministic Global Optimality
Due to the NP-hardness of many machine learning (ML) problems such as clustering, decision tree, and neural network, one primary belief is that solving ML problems to global optimality is computationally intractable. Based on this, the dominant methods in practice are based on either heuristics or local optimization algorithms, producing sub-optimal solutions. The other specious belief for the ML community is that, in the era of big data, simple models with strong interpretability (e.g., decision trees) cannot have the same predictive power as black-box models. In this project, we developed a series of scalable global optimization algorithms with deterministic global optimality guarantees that challenges the above prevailing mindsets with the following conclusions. 1) With the detection of problem structure, solving large-scale ML problems to global optimality is computationally feasible. 2) When the global optimality is obtained, the performance of highly interpretable ML models on large datasets can be substantially improved.
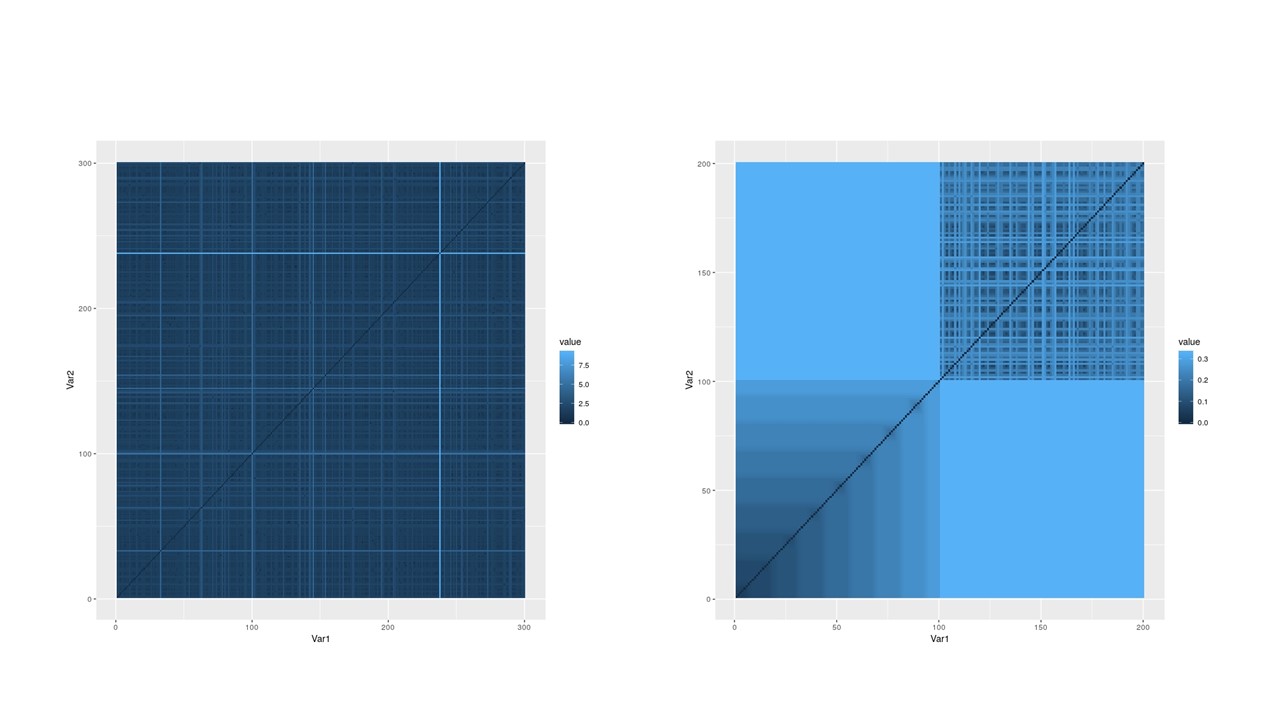
Ultrametricity and Clusterability
Clustering tendency is always an important issue for the community. Kleinberg’s impossibility theorem poses diffcult problems for users. The increasing need to cluster massive datasets and the high cost of running clustering algorithms prompt the requirements to determine if a data set is clusterable before users are running the clustering algorithm on the dataset. To detect whether a dataset has a cluster structure or is clusterable, that is, it may be partitioned efficiently into well-differentiated groups containing similar objects. We have to look for a proper way to measure the closeness between the original distance space and its corresponding benchmark space that is “most” clusterable. In this project, we approach data clusterability from an ultrametric- based perspective. A novel approach to determine the ultrametricity of a dataset is proposed via a particular type of matrix product, which allows us to evaluate the dataset’s clusterability. Furthermore, we show that applying our technique to a dissimilarity space will generate the sub-dominant ultrametric of the dissimilarity.
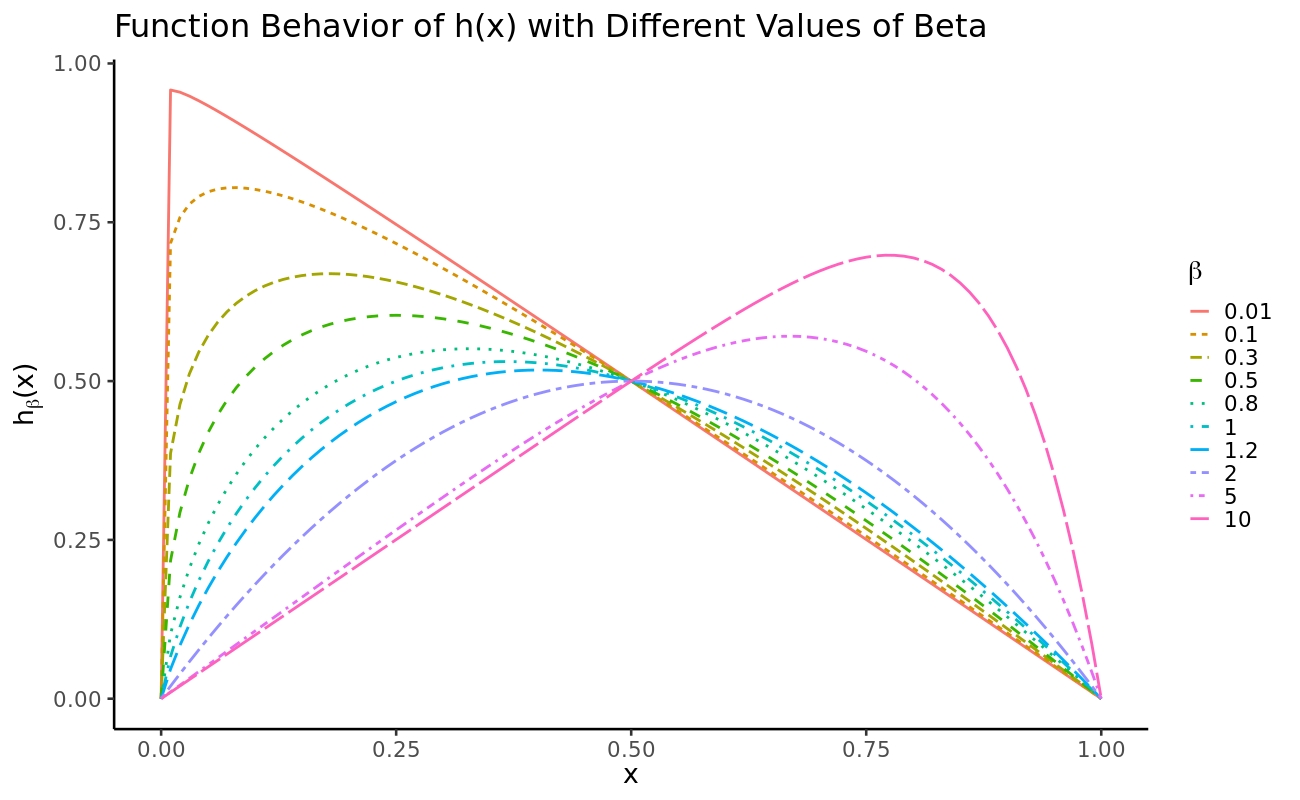
Unsupersived Model Selection on Dataset with Imbalanced clusters
Model selection remains a challenge in the machine learning field. In clustering, the problem will become the selection of the optimal k clusters. There are plenty of methods of guiding how to choose k. However, most of them will fail if the dataset has an imbalanced cluster structure.
In this theoretical project, we try to develop a technique grounded in information theory for determining the “natural” number of clusters existent in a data set, especially for dealing with clusterings of imbalanced data. Our approach involves a bi-criteria optimization that makes use of the entropy and the cohesion of a partition.
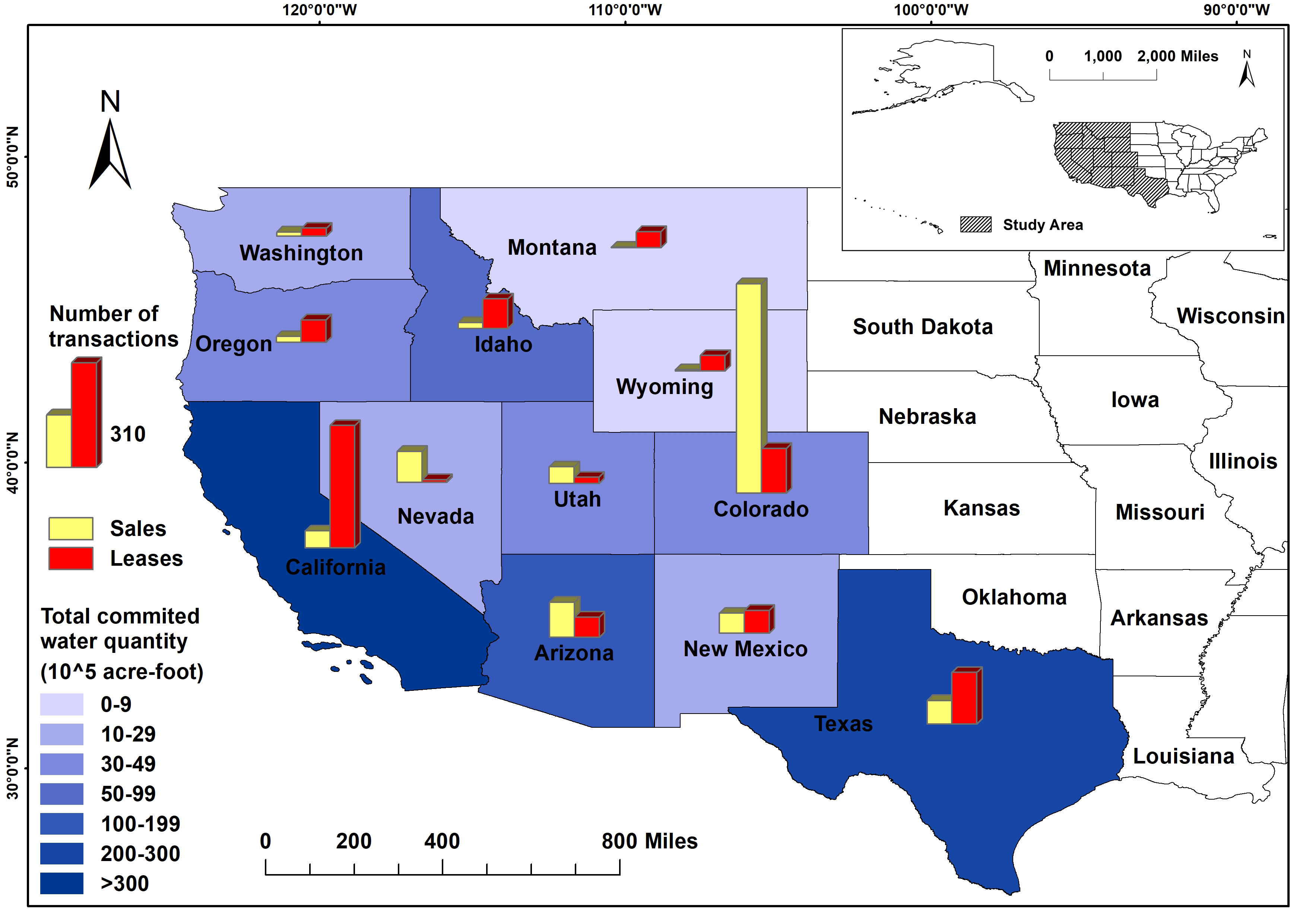
Water Price Prediction and Policy design
This project cooperates with the Ministry of Water Resources. It tends to take advantage of machine learning techniques to help the users and policy designers to have a clear expectation of future water prices.
Water trading is a special economic event. The price of water could vary primarily based on region, season, using purpose, or even buyer and seller’s current condition. Traditional methods for water trading price prediction have their limitations. Specifically, many non-linear correlations between different factors require more heuristic algorithms to enhance the prediction quality. This project aims to adopt or design some proper ML algorithms to have a better seasonal prediction and could also reveal the relationship and importance of different attributes.